 When we touch a hot stove, we quickly remove our hands and learn never to touch it again when it’s hot.
When we touch a hot stove, we quickly remove our hands and learn never to touch it again when it’s hot.
We all learn through feedback, from the searing pain of a hot stove to the warm praise of a job well done. It’s the cornerstone of growth, both in life and especially in the world of work.
As a senior engineer or tech lead, feedback is one of the most effective tools in your toolbox to help level up people around you.
But how do you give feedback effectively? For many, it’s shrouded in misconceptions and uncomfortable emotions.
It took me some time to understand some misconceptions I held about giving feedback. As an example, I once asked a report in a 1:1, What change can I make now to better support you? He responded, “I would love to receive more feedback from you.” I thought inwardly that I’m always on the lookout to see where I can give you feedback. You’re doing excellently well, and I can hardly find areas to suggest improvement.
One of the common misconceptions about giving feedback is that it should be given only when an opportunity for improvement is spotted. And I held on to that misconception for a while.
Ditch the myths
Let’s debunk some myths about giving feedback and explore the four simple steps to getting good at giving feedback.
Myth 1: Feedback is only for negative corrections. Not true! Feedback celebrates strengths, reinforces positive behaviors, and guides future actions; it is not always about fixing mistakes.
Myth 2: Instant feedback is always best. Emotions run high in the moment, leading to potentially hurtful and unproductive exchanges. Wait until you’re calm and collected.
Myth 3: Sandwiching is the way to go. Sugarcoating feedback dilutes its impact. Be direct, yet respectful.
Myth 4: You need a laundry list of examples. You don’t need a laundry list of examples to make your feedback effective. Focus on one or two key observations for clarity and impact.
Myth 5: Feedback is a one-way street. It’s a conversation! Encourage questions, active listening, and shared understanding.
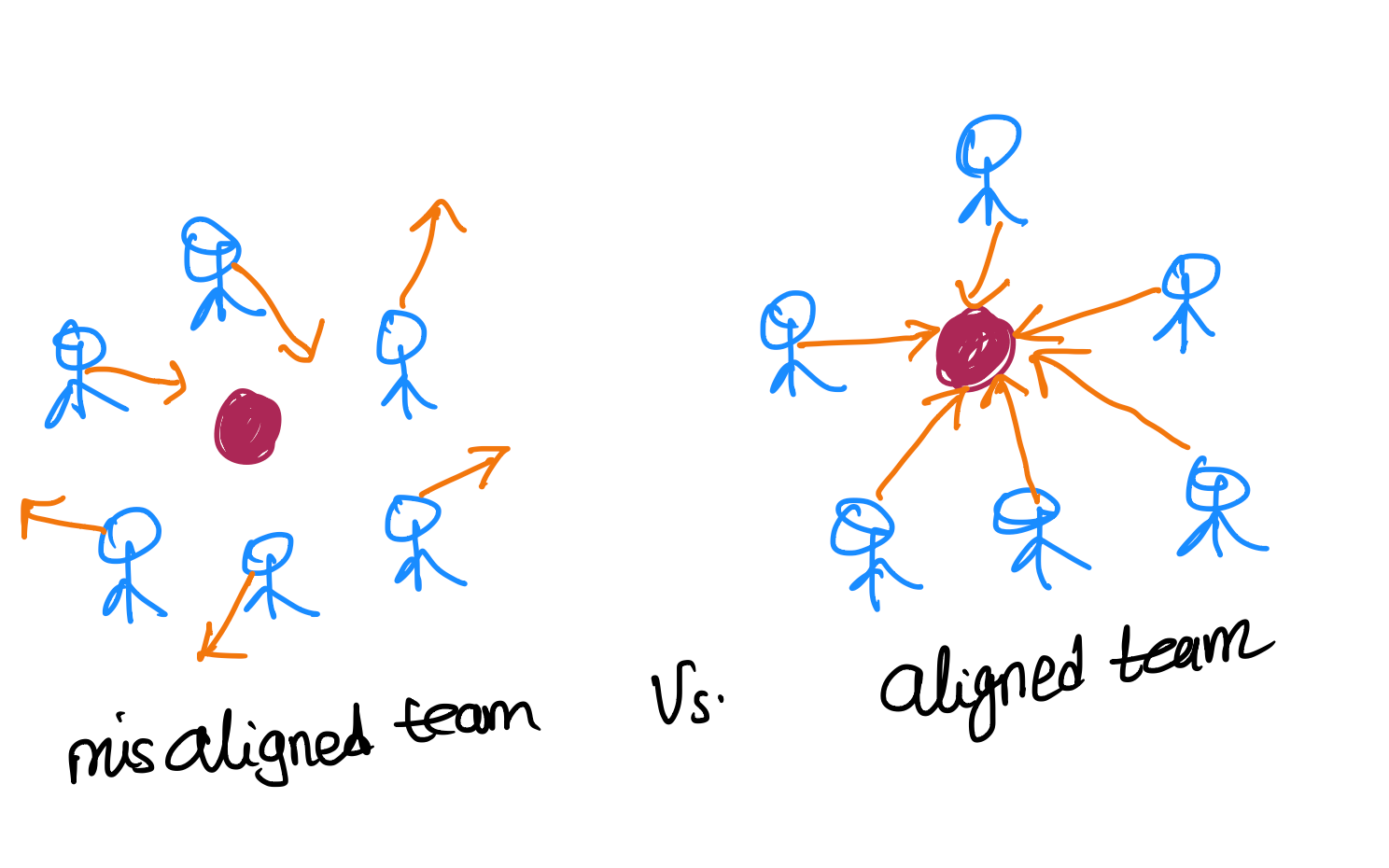
Myth 6: Feedback flows top-down only. High-performing teams have feedback flowing everywhere: leader-to-team, team-to-leader, and peer-to-peer.
Believing that you have to give feedback instantly can make you give feedback when you don’t have your emotions in check. You want to avoid giving feedback when you’re angry because it’s far more likely the recipient will feel hurt or judged—and thus defensive.
Feedback shouldn’t be given only when you want a change from the receiver. Feedback is not only about correcting mistakes and driving change but also about recognizing positive contributions and strengths and reinforcing positive behaviors.
Feedback is a two-way dialogue where both the giver and the receiver share their perspectives, ask questions, listen actively, and seek to understand each other.
Anyone can be both a giver and a receiver of feedback. It should not be a top-down thing. In a high-performing organization, feedback flows from top down (from managers to reports), down up (from reports to managers), and laterally (from peers to peers).
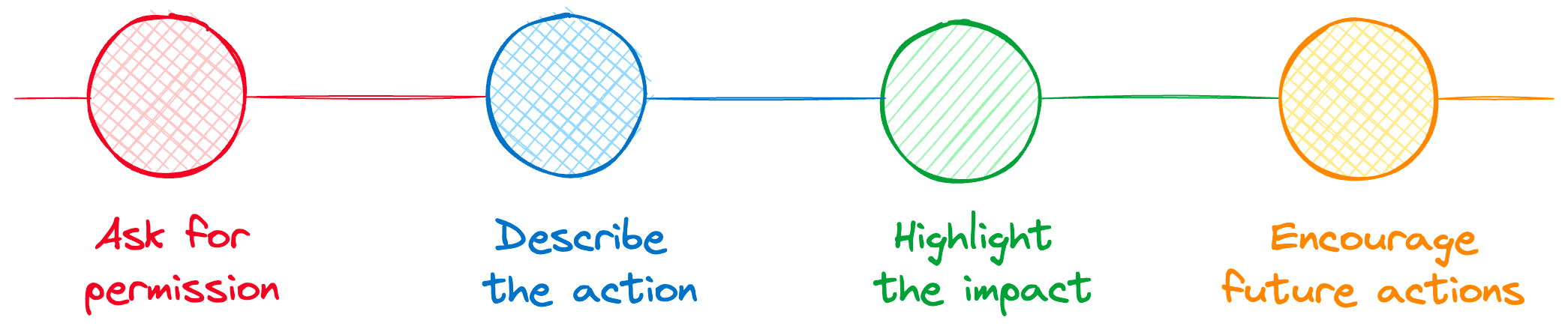
Four simple steps to get better at giving feedback.
Follow these four steps to offer better feedback.
1. Ask
Before diving in, ensure the recipient is open to hearing your thoughts. When you ask, it gives the receiver control, ensures that you have the attention of the person, and sets expectations for what the conversation will be about.
A simple question like “Can I share some feedback with you?” can do wonders.
2. Describe the behavior or action
Avoid judging intentions. As a feedback giver, your job is not to judge the intentions of others. You’re not in a position to put a label on the action. Your role is to express the impact their actions had on you, the team, or the project.
When feedback is focused on the past, the other party can’t do anything about it; defensiveness on the side of the receiver is sometimes inevitable. Good feedback should focus less on the past and more on the future, making the receiver feel that the purpose of the conversation is for the future.
The book Effective Managers describes a simple way of describing actions that I found useful. It starts with the “when” question. For example:
-
“When you took the initiative to…”
-
“When you presented today…”
-
“When you don’t communicate progress like you did yesterday…”
-
“When you spoke about…”
-
“When you stay an extra hour to find the root cause,”
-
“When you respond politely after the customer…”
-
“When you were presenting your ideas…”
3. Highlight the impact
Once you have described the action, proceed to explain how the behavior affected you, the team, or the project. For example, when you did that to XYZ, this is the impact (insert impact) it had on the team or the project.
Example:”
Behavior: When you took the initiative to…
Impact: This helped the team move forward efficiently and be able to deliver on time.
4. Encourage future action
If the feedback is negative, suggest what could be done differently in the future. If it’s positive, express appreciation and encourage continued behavior.
Building trust is key
Trust is like the air we breathe; when it’s present, nobody really notices; when it’s absent, everybody notices. – Warren Edward Buffett.
When people trust the giver, they’re more receptive and open to learning. Invest time in building genuine connections with your team. This fosters an environment where feedback is seen as a tool for growth, not criticism.
In conclusion, giving feedback is a skill that can be learned, not a magic trick. By practicing these steps and fostering a culture of trust, you can unlock the true power of feedback.
]]>




{kind=link}
{kind=link}
{kind=link}